Data Warehouse
Star/Snowflake schema, OLAP vs OLTP, staging/prod/replica.
Data Warehouse — почему аналитику нельзя делать на продакшн-базе
Загрузка интерактивного виджета...
🗺️ Где это в общей картине
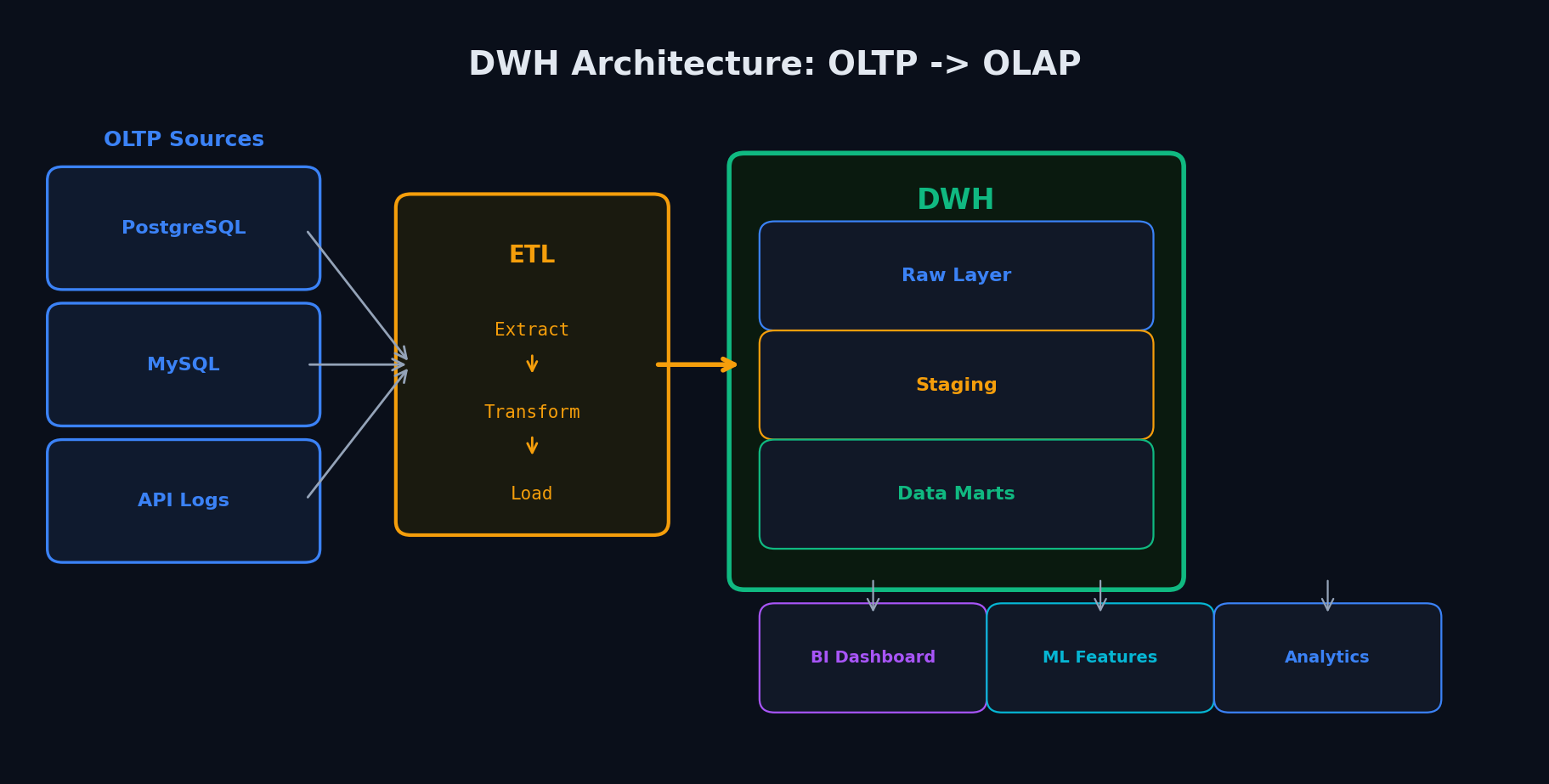
DWH vs обычная база — OLTP vs OLAP
Обычная база (PostgreSQL, MySQL) — это OLTP: быстро записать заказ, обновить статус, достать конкретного пользователя по id. Данные хранятся построчно — вся строка рядом на диске. А когда аналитик запускает SELECT SUM(revenue) GROUP BY region на 500 млн строк — база тормозит, а заодно тормозит и прод.
DWH (Data Warehouse) — это OLAP: отдельное хранилище, заточенное под аналитику. Данные хранятся по колонкам — все значения одного столбца рядом. Чтобы посчитать SUM(revenue), DWH читает только столбец revenue, а не всю таблицу. Прод живёт отдельно, аналитика — отдельно.
- OLTP: INSERT одной строки за микросекунды. PostgreSQL, MySQL. Для приложений
- OLAP: SUM/AVG по миллиардам строк за секунды. ClickHouse, BigQuery, Snowflake. Для аналитики и ML
Конкретные DWH-решения
В зависимости от компании и стека ты встретишь разные DWH:
- ClickHouse — колоночная СУБД, очень популярна в РФ. Быстрая, open-source, хороша для real-time аналитики
- BigQuery (Google Cloud) — serverless DWH: не нужно управлять серверами, платишь за запросы. Стандарт в GCP-стеке
- Snowflake — облачный DWH с разделением хранения и вычислений. Популярен в западных компаниях
- Redshift (AWS) — DWH от Amazon. Если компания на AWS — скорее всего Redshift
Star Schema — главная модель данных в DWH
Star Schema — это когда в центре таблица фактов с числами (revenue, quantity), а вокруг — таблицы измерений с атрибутами (кто, что, когда). Факты ссылаются на измерения через ключи. Всё денормализовано для быстрых аналитических запросов.
-- Типичный запрос к Star Schema — revenue по сегментам
SELECT d.month, u.segment, SUM(f.revenue) AS total_revenue
FROM fact_orders f
JOIN dim_date d ON f.date_key = d.date_key
JOIN dim_users u ON f.user_key = u.user_key
WHERE d.year = 2024
GROUP BY d.month, u.segment
ORDER BY d.month, total_revenue DESC;Слои DWH — от сырых данных до готовых фичей
Данные проходят несколько слоёв. Это не бюрократия — если что-то сломалось на уровне трансформаций, можно откатиться к сырым данным и пересчитать.
- Staging (STG) — сырые данные «как есть» из источников. Минимум обработки, полная копия
- DWH (Core) — очищенные данные в единой модели (Star Schema). Единый источник правды
- Data Mart (витрины) — готовые агрегаты под конкретные задачи: ML-фичи, дашборды, отчёты
Как ML-инженер работает с DWH
ML-инженер взаимодействует с DWH в двух направлениях. Читаешь: берёшь данные из витрин для feature engineering — user-level агрегаты, поведенческие метрики, транзакционные фичи. Пишешь: результаты инференса модели (предсказания, скоры) кладёшь обратно в DWH, чтобы аналитики и бизнес могли их использовать.
-- Витрина для ML — одна строка на пользователя
CREATE TABLE mart_user_features AS
SELECT
u.user_id,
u.segment,
COUNT(f.order_id) AS total_orders_30d,
SUM(f.revenue) AS total_revenue_30d,
AVG(f.revenue) AS avg_order_value,
CURRENT_DATE - MAX(d.full_date) AS days_since_last_order
FROM dim_users u
LEFT JOIN fact_orders f ON u.user_key = f.user_key
LEFT JOIN dim_date d ON f.date_key = d.date_key
WHERE d.full_date >= CURRENT_DATE - INTERVAL '30 days'
GROUP BY u.user_id, u.segment;Современный data stack
- Cloud DWH: BigQuery, Snowflake, Redshift — платишь за запросы, масштабируется автоматически
- dbt (data build tool) — SQL-трансформации как код, с тестами и документацией в Git. Стандарт индустрии
- Data Lake: S3/GCS + Parquet — дешёвое хранение сырых данных. DWH строится поверх
- Lakehouse: Delta Lake, Apache Iceberg — гибрид Lake + DWH: ACID-транзакции на файлах в S3
💡 Как это в реальной работе
🎯 На собесе
Материалы
Подробный разбор схем DWH на русском.
Основы dimensional modeling от создателей dbt.
Понятное объяснение DWH за 15 минут.
Классические техники моделирования от Кимбалла — для углублённого изучения.