Data Quality
Great Expectations, dbt tests, data contracts — контроль качества данных.
Data Quality — мусор на входе = мусор на выходе
Garbage in — garbage out. Самая крутая модель бессильна, если в данных дубликаты, пропуски или невалидные значения. Но проблема глубже: данные ломаются тихо. Бэкенд-команда переименовала поле, ETL-пайплайн продолжает работать (просто столбец стал NULL), модель тренируется на мусоре — и через неделю бизнес замечает, что конверсия просела. Data Quality — это автоматические проверки на каждом этапе пайплайна, а не «посмотрел глазами и вроде ок».
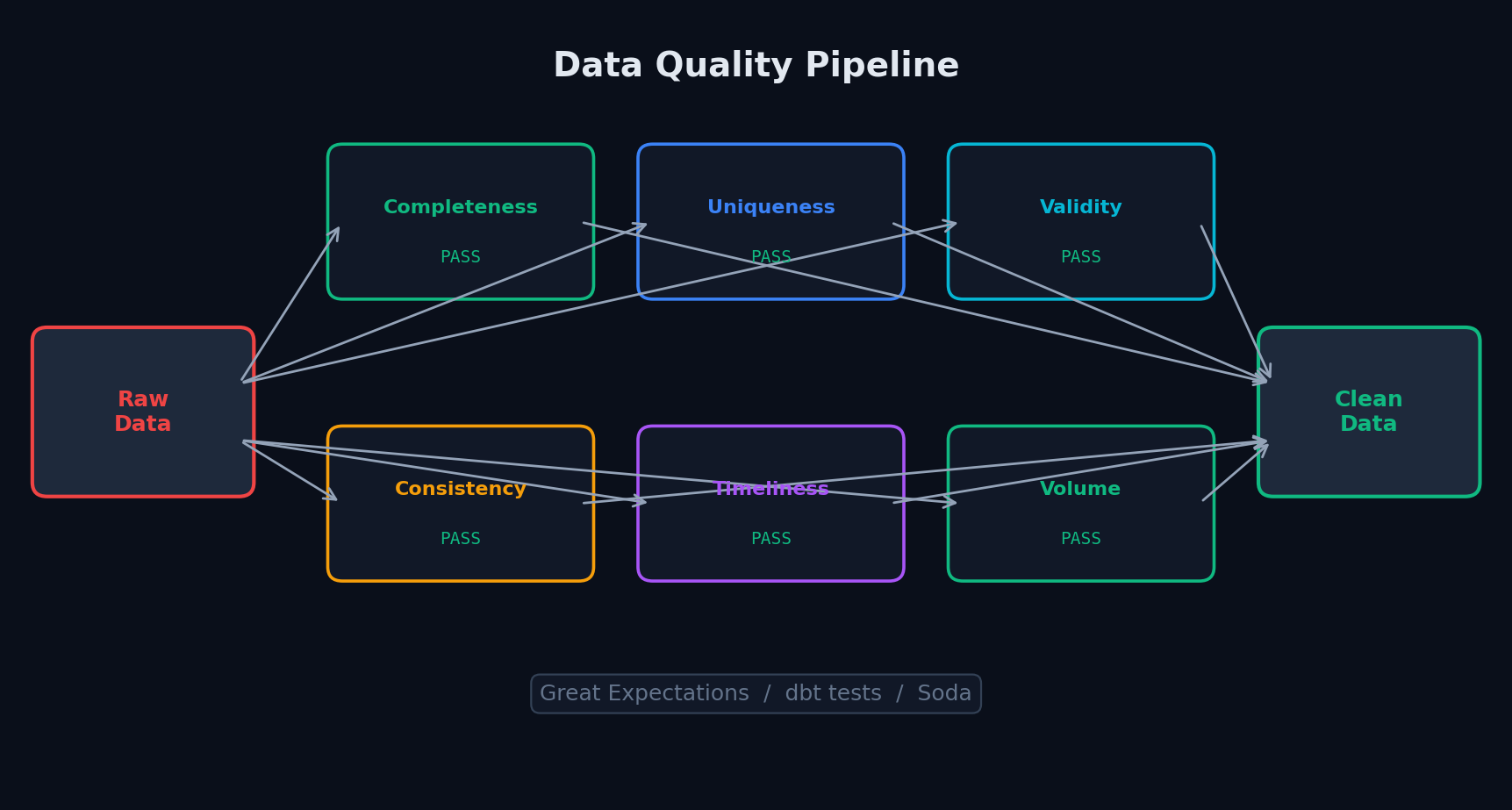
Что проверять — чек-лист
- Completeness — нет ли пропусков? NULL в user_id = потерянные данные
- Uniqueness — нет ли дубликатов? Один order_id должен встречаться один раз
- Validity — значения в допустимых границах? Возраст 0-120, цена > 0, email содержит @
- Consistency — данные согласованы между таблицами? Все order.user_id есть в users
- Timeliness — данные свежие? Последняя запись не старше 2 часов
- Volume — объём в ожидаемом диапазоне? Обычно 100K событий в час, вдруг стало 0 или 10M
Great Expectations — автоматические проверки в Python
Great Expectations (GX) — Python-библиотека для декларативных проверок данных. Описываешь ожидания (expectations): «user_id не NULL», «order_id уникален», «amount от 0 до 1M», «status из списка [pending, completed, cancelled]». GX проверяет и генерирует HTML-отчёт. Если что-то не так — пайплайн останавливается. Интегрируется с Airflow, Spark, pandas.
import great_expectations as gx
context = gx.get_context()
suite = context.add_expectation_suite("orders_quality")
# Декларативные проверки — каждая описывает одно ожидание
suite.add_expectation(gx.expectations.ExpectColumnValuesToNotBeNull(column="user_id"))
suite.add_expectation(gx.expectations.ExpectColumnValuesToBeUnique(column="order_id"))
suite.add_expectation(gx.expectations.ExpectColumnValuesToBeBetween(
column="amount", min_value=0, max_value=))
suite.add_expectation(gx.expectations.ExpectTableRowCountToBeBetween(
min_value=1000, max_value=))
# results.success → прошло или нетdbt tests — проверки прямо в SQL-пайплайне
Если ты уже используешь dbt для трансформаций — проверки данных встраиваются бесплатно. Generic tests (unique, not_null, relationships, accepted_values) описываются в YAML в паре строк. Для сложных проверок — custom SQL test: пишешь SELECT, если запрос вернул строки — тест провален.
# models/schema.yml — проверки в пару строк
models:
- name: stg_orders
columns:
- name: order_id
tests: [unique, not_null]
- name: user_id
tests:
- not_null
- relationships:
to: ref('stg_users')
field: user_id
- name: amount
tests:
- not_null
- dbt_utils.accepted_range:
min_value: 0
- name: status
tests:
- accepted_values:
values: ['pending', 'completed', 'cancelled']Для проверки свежести данных пишешь custom test — SQL-файл в папке tests/. Например, SELECT 1 WHERE MAX(created_at) < CURRENT_TIMESTAMP - INTERVAL '2 hours' — если данные устарели, тест упадёт. Команда dbt test запускается после dbt run в Airflow — если тест упал, модель не переобучается на битых данных.
Data Contracts — договариваемся с бэкенд-командой
Data Contract — соглашение между тем, кто генерирует данные (бэкенд), и тем, кто их использует (ML-команда). Описывает: какие поля, какие типы, какая свежесть, какой объём. Если бэкенд меняет схему без согласования — контракт нарушен, срабатывает алерт. Контракт описывается в YAML (имя, версия, owner, schema с типами и enum, SLA по freshness и volume, список consumers). Без контрактов — каждая вторая поломка пайплайна из-за «мы переименовали поле, а кто-то ещё его использует?».
💡 Как это в реальной работе
💡 Data Quality перед обучением модели
🎯 На собесе