Введение в Computer Vision
Задачи CV, ключевые датасеты (ImageNet, COCO), история от фильтров до трансформеров, карьера CV-инженера.
Computer Vision — как научить машину видеть
Человек получает 80% информации через зрение. Мы мгновенно распознаём лица, читаем текст, определяем расстояние до объектов — и делаем это без усилий. Computer Vision (CV) — это область ИИ, которая учит машины делать то же самое: извлекать смысл из изображений и видео.
CV — не нишевая область. Это одна из трёх ключевых специализаций ML-инженера (вместе с NLP и RecSys). Автопилоты Tesla обрабатывают 8 камер в реальном времени. Системы видеонаблюдения анализируют миллионы потоков. Медицинская диагностика по рентгенам уже на уровне врачей. Генерация изображений (DALL-E, Midjourney, Stable Diffusion) перевернула креативную индустрию.
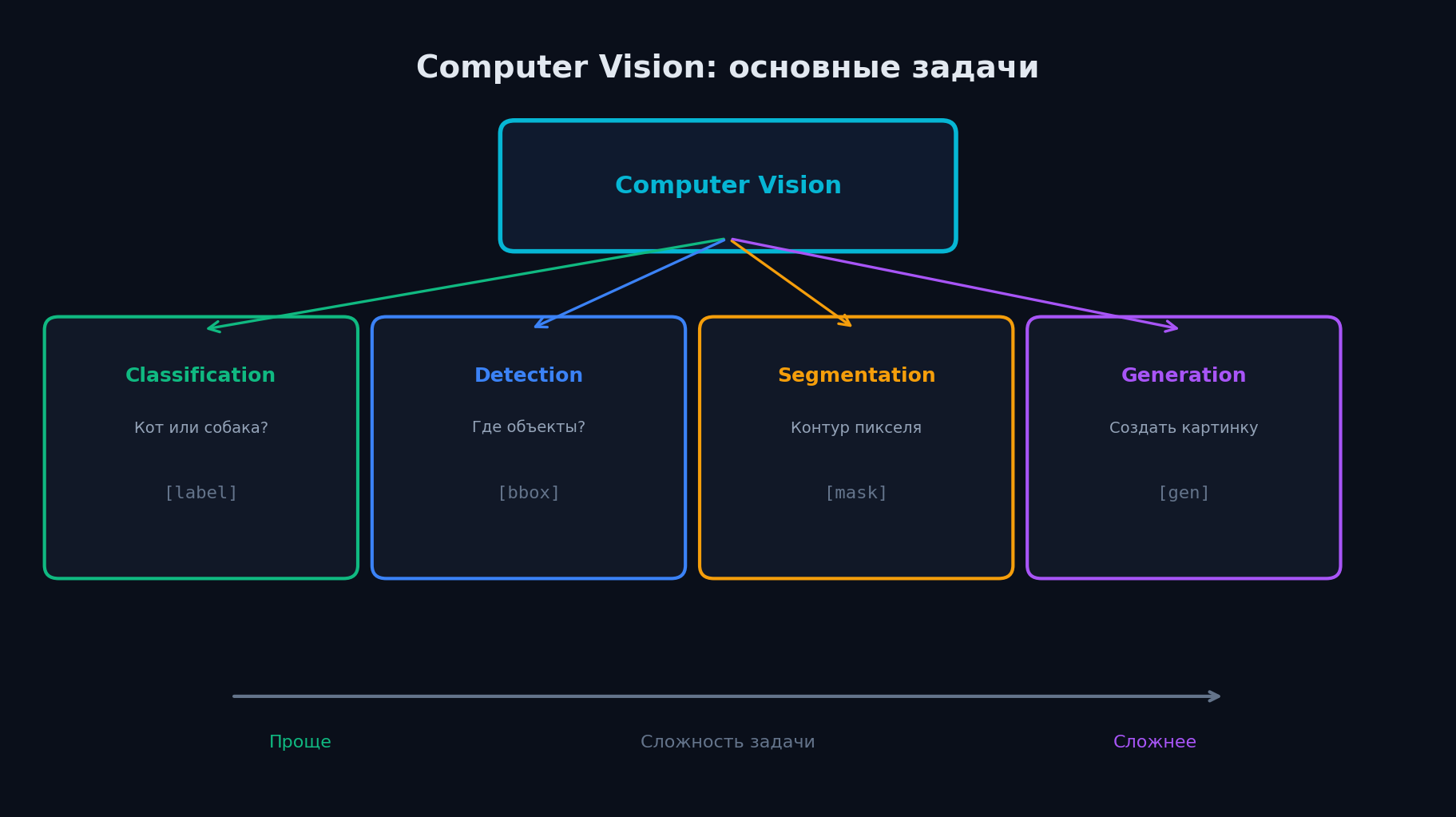
Основные задачи CV
Все задачи CV можно разложить на несколько фундаментальных типов. Каждый последующий сложнее предыдущего:
- Image Classification — «что на картинке?». Один лейбл на всё изображение. ImageNet: 1000 классов, top-5 accuracy. Базовая задача, с которой начинался deep learning в CV (AlexNet, 2012).
- Object Detection — «что и где?». Bounding boxes + классы для каждого объекта. COCO: 80 классов, метрика mAP. Ключевая задача для автопилотов, видеонаблюдения, робототехники.
- Semantic Segmentation — «какой класс у каждого пикселя?». Попиксельная классификация без разделения экземпляров. Медицина (опухоли на МРТ), автономное вождение (дорога/тротуар/машины).
- Instance Segmentation — «где каждый отдельный объект?». Как semantic, но различает отдельные экземпляры: две машины — два разных маска. Mask R-CNN — классический подход.
- Image Generation — «создай изображение по описанию». GAN, VAE, Diffusion Models. Stable Diffusion генерирует фотореалистичные изображения по текстовому промпту.
- Other tasks — pose estimation (скелеты людей), depth estimation (карта глубины), OCR (распознавание текста), face recognition, image super-resolution, video understanding.
Ключевые датасеты
Прогресс CV измеряется на стандартных бенчмарках. Знание датасетов — обязательно для собеседований:
- ImageNet (ILSVRC) — 1.2M изображений, 1000 классов. Бенчмарк для классификации. Top-1 accuracy: AlexNet (2012) — 63%, ResNet (2015) — 76%, ViT (2021) — 88%+. ImageNet буквально определил ход развития deep learning.
- COCO (Common Objects in Context) — 330K изображений, 80 классов объектов. Стандарт для detection и segmentation. Метрика: mAP@[0.5:0.95]. Содержит bounding boxes, маски, keypoints, captions.
- Pascal VOC — предшественник COCO. 20 классов, ~11K изображений. Исторически важен, но сейчас уступил COCO.
- CIFAR-10/100 — 60K маленьких (32×32) изображений. 10 или 100 классов. Удобен для экспериментов — быстро тренировать, легко итерировать.
- ADE20K — 25K изображений с dense-аннотациями для semantic segmentation. 150 категорий. Стандарт для оценки сегментации.
- Open Images — 9M изображений от Google. Один из крупнейших открытых датасетов с bounding boxes, масками и visual relationships.
Краткая история CV: от фильтров к трансформерам
До 2012: классический CV — ручные фичи (SIFT, HOG, Haar cascades), SVM для классификации. Каждую задачу решали отдельным пайплайном. Работало, но медленно, хрупко, требовало экспертизы в предметной области.
2012 — AlexNet: Krizhevsky, Sutskever & Hinton выиграли ImageNet с CNN на GPU. Ошибка top-5 упала с 26% до 16% — прорыв. Началась эра deep learning в CV.
2012–2020 — эра CNN: VGG (глубина), GoogLeNet (параллельные пути), ResNet (skip connections), EfficientNet (scale). Detection: R-CNN → Fast → Faster R-CNN → YOLO. Segmentation: FCN → U-Net → DeepLab.
2020+ — эра трансформеров: Vision Transformer (ViT) показал, что трансформеры работают и для картинок. Swin Transformer, DINO, MAE, SAM (Segment Anything). Параллельно — диффузионные модели для генерации (DALL-E 2, Stable Diffusion, Midjourney).
CV-инженер на рынке труда
CV — одна из самых востребованных ML-специализаций. Основные направления:
- Автономное вождение — Tesla, Waymo, Яндекс.Беспилотники. Детекция, сегментация, depth estimation в реальном времени.
- Медицина — анализ рентгенов, МРТ, гистологических срезов. Регулируемая область, но с огромным потенциалом.
- Видеоаналитика / безопасность — распознавание лиц, подсчёт людей, трекинг, детекция аномалий.
- Генеративные модели — Midjourney, Stable Diffusion, видеогенерация (Sora). Растущий рынок.
- Промышленность — контроль качества (дефекты на производстве), робототехника, дроны.
- E-commerce — visual search, virtual try-on, автоматическая модерация контента.
🎯 На собеседовании
Базовые вопросы
Что дальше
Материалы
Лучший академический курс по CV. Лекции, assignments, notes — всё в открытом доступе.
Видеозаписи лекций CS231n 2017. Karpathy и Fei-Fei Li — отличные лекторы.
Обзор основных задач CV на русском.