3D Vision
Depth estimation (MiDaS), Point Clouds (PointNet), NeRF, 3D Gaussian Splatting.
3D Vision — глубина, облака точек и NeRF
Мир трёхмерный, а камеры дают 2D-проекцию. 3D Vision восстанавливает третье измерение: глубину, форму объектов, 3D-структуру сцены. Это критично для автономного вождения (где препятствие?), робототехники (как схватить объект?), AR/VR (как вписать виртуальный объект в реальную сцену?).
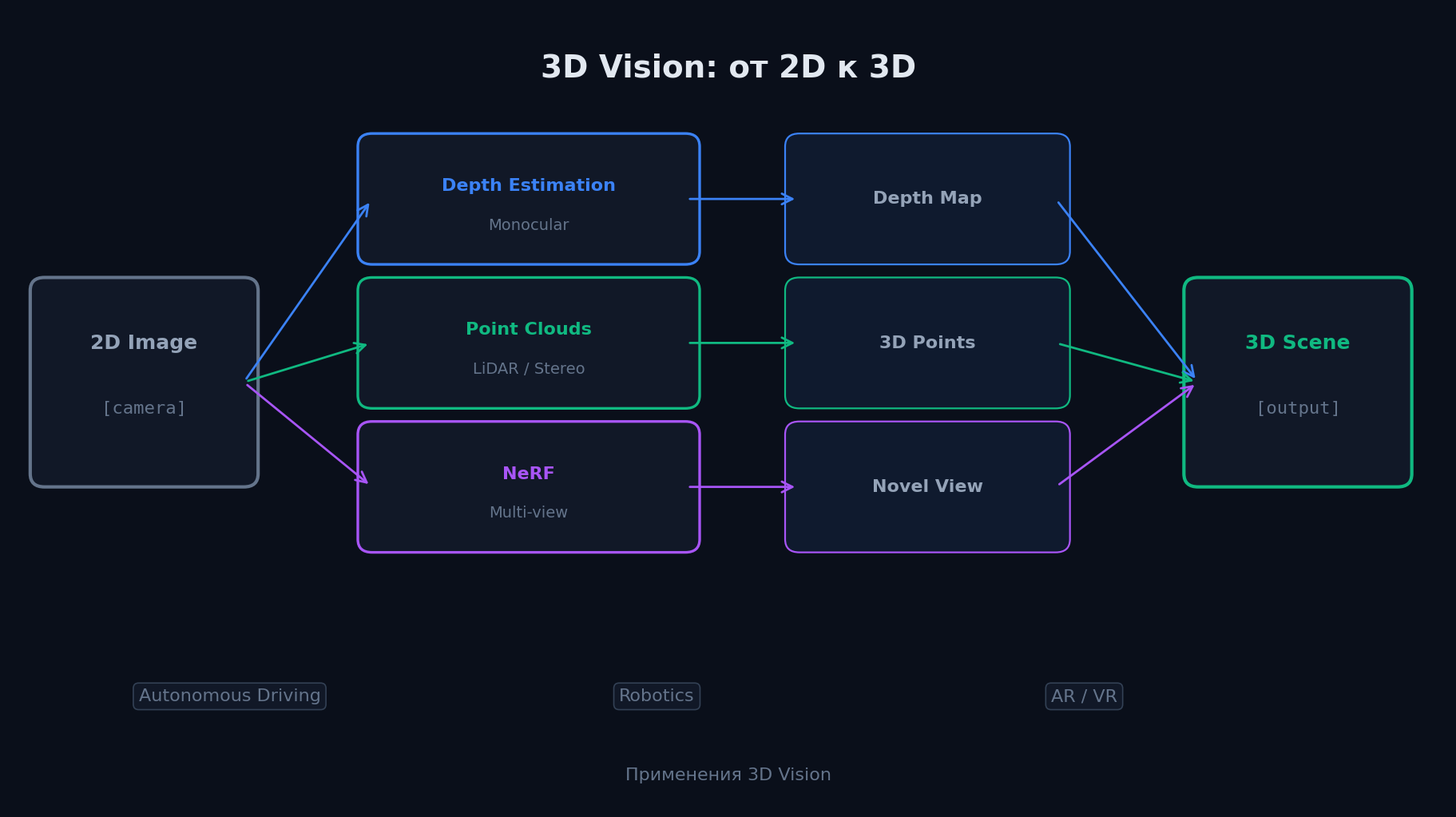
Depth Estimation — карта глубины
Monocular depth estimation — предсказание глубины по одному изображению. Задача ill-posed (бесконечно много 3D-сцен дают одну 2D-проекцию), но нейросети удивительно хорошо справляются:
- MiDaS / DPT — лучшие zero-shot модели на основе ViT. Предсказывают relative depth (порядок глубин, но не метрические значения). Работают на произвольных изображениях.
- Metric depth — ZoeDepth, Metric3D предсказывают абсолютную глубину в метрах. Нужна калибровка или domain-specific training.
- Stereo matching — две камеры → disparity map → depth. Классический подход. RAFT-Stereo — SOTA нейросетевой метод.
- Lidar — лазерный сенсор даёт точные 3D-измерения. Используется в автопилотах. Дорогой, но точный.
Point Clouds и PointNet
Point cloud — неупорядоченное множество 3D-точек {(x, y, z)} от лидара или depth-камеры. Ключевая проблема: обычные CNN не работают с неупорядоченными множествами.
- PointNet (2017) — обрабатывает каждую точку независимо (shared MLP), затем symmetric function (max pooling) для инвариантности к порядку. Простой, но мощный.
- PointNet++ — добавляет иерархическую структуру через set abstraction (группировка соседних точек). Учитывает локальную геометрию.
- Voxelization — преобразование point cloud в 3D-сетку (воксели) → 3D CNN. VoxNet, MinkowskiNet. Проще, но дороже по памяти.
- Point Transformer — self-attention на point clouds. Эффективнее PointNet++ на больших сценах.
NeRF — Neural Radiance Fields
NeRF (2020) — революция в 3D-реконструкции. Обучает MLP предсказывать цвет и плотность в каждой 3D-точке по координатам (x, y, z) и направлению взгляда (θ, φ). Volume rendering → фотореалистичные новые ракурсы сцены.
- Вход — набор 2D-фотографий с известными позициями камер (COLMAP для оценки).
- Positional encoding — sin/cos кодирование координат для высокочастотных деталей.
- Volume rendering — луч из камеры → sampling точек → MLP предсказывает (цвет, плотность) → интеграция вдоль луча → пиксель.
- Ограничения — медленный рендеринг (~30с на кадр), нужен час+ на обучение одной сцены.
- Instant-NGP (NVIDIA) — ускорил NeRF до real-time через hash-based positional encoding. Обучение за минуты вместо часов.
- 3D Gaussian Splatting (2023) — альтернатива NeRF. Явное 3D-представление (gaussian ellipsoids) вместо implicit MLP. Real-time рендеринг, быстрее обучение.
🎯 На собеседовании
Частые вопросы
Материалы
NeRF — implicit 3D representation через MLP. Одна из самых цитируемых CV-статей 2020-х.
PointNet — первая успешная нейросеть для point clouds. Ключевая идея: per-point MLP + max pooling.
Gaussian Splatting — real-time альтернатива NeRF. Explicit 3D representation.