Основы MLOps
Docker, DVC, MLflow, эксперименты — как довести модель до продакшна.
MLOps — как довести модель от Jupyter до продакшна
Ты обучил модель в Jupyter-ноутбуке, получил AUC 0.93 и показал коллегам. Все довольны. А потом начинается реальность: как упаковать модель, чтобы она работала не только на твоём ноутбуке? Как обновлять её, когда данные изменились? Как понять, что модель деградировала на проде? Как откатиться к предыдущей версии?
MLOps — это набор практик, которые отвечают на эти вопросы. По сути, это DevOps, адаптированный для ML: версионирование данных и моделей, автоматизация обучения, CI/CD для ML-пайплайнов, деплой и мониторинг. Обучить модель — это 10-20% работы. Остальные 80% — довести её до продакшна и поддерживать.
Аналогия: написать прототип приложения — одно дело. Запустить его на миллион пользователей с мониторингом, обновлениями и отказоустойчивостью — совсем другое. MLOps — это мост между «модель работает в ноутбуке» и «модель приносит деньги в продакшне».
Большая картина: жизненный цикл ML-системы
ML-система — это не «обучил и забыл». Это непрерывный цикл из пяти фаз, который крутится, пока модель жива:
1. Develop — формулируешь задачу, собираешь данные, делаешь EDA, выбираешь baseline. Основной инструмент — Jupyter, Python, pandas. 2. Train — обучаешь модели, подбираешь гиперпараметры, логируешь эксперименты (MLflow, W&B). Каждый запуск трекается: параметры, метрики, артефакты. 3. Deploy — упаковываешь модель (Docker), оборачиваешь в API (FastAPI/gRPC), деплоишь на сервер или в облако. CI/CD автоматизирует этот процесс. 4. Monitor — отслеживаешь качество модели на продакшне. Data drift, model drift, latency, ошибки. Алерты, когда что-то пошло не так. 5. Retrain — когда мониторинг показал деградацию, запускаешь переобучение на свежих данных. И цикл начинается заново.

Зачем это DS-у?
Experiment Tracking: MLflow и W&B
Ты запустил 50 экспериментов с разными гиперпараметрами. Какой дал лучший результат? С какой learning rate? На какой версии данных? Без трекинга — хаос из ноутбуков и Slack-сообщений «лучшая модель — третий запуск во вторник».
Experiment tracking решает это системно. Каждый запуск обучения автоматически логирует: • Параметры — гиперпараметры (lr, batch_size, epochs), версию данных, seed • Метрики — loss, AUC, F1, precision/recall по эпохам • Артефакты — сохранённую модель, графики обучения, confusion matrix • Окружение — версии библиотек, hardware, git commit Два главных инструмента: MLflow (open-source, self-hosted) и Weights & Biases (облачный, бесплатный для индивидуального использования).
# MLflow — логируем эксперимент
import mlflow
with mlflow.start_run(run_name="catboost-v3"):
mlflow.log_param("learning_rate", 0.05)
mlflow.log_param("depth", 6)
mlflow.log_param("iterations", 1000)
model = train_catboost(params)
mlflow.log_metric("auc_train", 0.96)
mlflow.log_metric("auc_val", 0.93)
mlflow.log_metric("f1_val", 0.87)
# Сохраняем модель как артефакт
mlflow.catboost.log_model(model, "model")
# Теперь можно сравнить все 50 запусков в UI# W&B — аналогично, но с автоматическими графиками
import wandb
wandb.init(project="churn-prediction", name="catboost-v3")
wandb.config.update({"lr": 0.05, "depth": 6, "iterations": 1000})
for epoch in range(100):
loss, auc = train_epoch(model, data)
wandb.log({"loss": loss, "auc": auc, "epoch": epoch})
wandb.finish() # → красивые графики в браузереMLflow vs W&B: MLflow — self-hosted, полный контроль над данными, бесплатный. W&B — облачный, красивый UI, автоматические графики, удобный для команд. В enterprise чаще MLflow (данные не уходят наружу). В стартапах и для pet-проектов — W&B.
Model Registry: версионирование моделей
Experiment tracking логирует запуски. Model Registry — следующий уровень: он хранит конкретные модели с версиями и стадиями жизненного цикла.
Аналогия: experiment tracking — это Git log (история всех коммитов). Model registry — это Git tags и branches: ты помечаешь «эта модель — production v3», «эта — staging, тестируем», «эта — archived, была плохая».
Типичный workflow: 1. Обучил модель → она появляется в experiment tracking как один из 50 запусков 2. Лучшую модель регистрируешь в Model Registry → она получает имя (churn-model) и версию (v3) 3. Присваиваешь стадию: Staging → тестирование на shadow traffic 4. Если тесты пройдены → переводишь в Production → модель деплоится автоматически 5. Старая production-модель → Archived MLflow Model Registry поддерживает стадии из коробки. В W&B аналог — Model Registry с aliases (production, staging, latest).
# MLflow Model Registry
import mlflow
# Регистрируем лучшую модель
result = mlflow.register_model(
model_uri="runs:/abc123/model",
name="churn-model"
) # → churn-model version 3
# Переводим в production
from mlflow.tracking import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name="churn-model",
version=3,
stage="Production"
)
# В inference-сервисе загружаем всегда production-версию
model = mlflow.pyfunc.load_model("models:/churn-model/Production")CI/CD для ML: тестирование данных, модели и кода
В обычном софте CI/CD — это автоматические тесты и деплой при каждом коммите. В ML всё сложнее: помимо кода нужно тестировать данные и модель. Три уровня тестов:
Тесты кода — стандартные unit/integration тесты: функции предобработки возвращают правильные типы, API отвечает 200, пайплайн не падает. Тесты данных — проверяешь свежие данные перед обучением: нет ли пропусков, не сдвинулось ли распределение, нет ли дупликатов, валидны ли типы. Инструменты: Great Expectations, Pandera, dbt tests. Тесты модели — после обучения: метрики не хуже baseline (AUC ≥ 0.90), модель не деградировала на ключевых сегментах, inference-время ≤ 100ms, модель не предсказывает «всем 0».
# Пример: тесты данных + модели в CI
def test_data_quality(df):
"""Запускается в CI перед обучением"""
assert df.isna().sum().sum() == 0, "Есть пропуски"
assert df["age"].between(0, 120).all(), "Аномальный возраст"
assert len(df) > , "Слишком мало данных"
def test_model_quality(model, test_data):
"""Запускается в CI после обучения"""
preds = model.predict(test_data.X)
auc = roc_auc_score(test_data.y, preds)
assert auc >= 0.90, f"AUC {auc:.3f} < 0.90 — модель деградировала"
# Проверяем ключевые сегменты
for segment in ["premium", "new_users"]:
seg_auc = calc_auc(model, test_data, segment)
assert seg_auc >= 0.85, f"{segment}: AUC {seg_auc:.3f} < 0.85"Типичный ML CI/CD пайплайн на GitHub Actions: push → lint + unit-тесты → тесты данных → обучение → тесты модели → регистрация в Model Registry → деплой на staging → smoke-тесты → деплой на production.
Feature Store: единый источник фичей
Представь: команда антифрода считает фичу «количество транзакций за 7 дней» в Spark-джобе. Команда рекомендаций считает ту же фичу — но в другом пайплайне, немного по-другому. Команда скоринга — третий вариант. Три реализации одной фичи — три источника багов.
Feature Store решает это: одно место, где фичи вычисляются, хранятся и отдаются. Считаешь фичу один раз — используешь везде. Главный бонус: гарантия, что в обучении и на инференсе используются одинаковые фичи (training-serving skew — одна из самых коварных ошибок в ML).
Два режима: • Offline store — для обучения. Хранит исторические значения фичей. Реализация: таблицы в S3/BigQuery/Hive. Запрос: «дай мне фичи всех пользователей на дату X». • Online store — для инференса. Хранит последние значения фичей с минимальной latency. Реализация: Redis, DynamoDB. Запрос: «дай мне фичи пользователя 42 прямо сейчас». Инструменты: Feast (open-source), Tecton, Vertex AI Feature Store (GCP). Для небольших команд feature store — это часто просто Redis + cron-джоба, а не отдельная платформа.
Model Serving: batch vs online inference
Модель обучена, зарегистрирована, протестирована. Теперь её нужно использовать — делать предсказания. Есть два принципиально разных режима:
Batch inference — предсказания заранее, для всех. Раз в час/день прогоняешь модель на всей базе, результаты складываешь в таблицу. Примеры: рекомендации для email-рассылки, скоринг всех клиентов для CRM, предсказание оттока на завтра. *Когда использовать:* предсказания не нужны в реальном времени. Latency не критична. Простая инфраструктура: cron + Spark/pandas. Online inference — предсказание в реальном времени по запросу. Пользователь открывает приложение → сервер запрашивает модель → получает ответ за 50-200ms → показывает рекомендации. *Когда использовать:* latency критична, контекст зависит от текущего запроса (поисковая выдача, антифрод, чат-бот). Инфраструктура сложнее: API-сервис, автоскейлинг, health-чеки.
# Online serving — FastAPI
from fastapi import FastAPI
import mlflow
app = FastAPI()
model = mlflow.pyfunc.load_model("models:/churn-model/Production")
@app.post("/predict")
async def predict(features: dict):
prediction = model.predict([features])
return {"churn_probability": float(prediction[0])}
# Batch serving — cron + pandas
def batch_predict():
"""Запускается по cron раз в день"""
users = load_all_users() # 1M строк
predictions = model.predict(users) # batch предсказания
save_to_db(predictions) # результаты в таблицуLatency budget — ключевой параметр для online serving. Типичные ограничения: рекомендации — 100-200ms, антифрод — 50ms, автокомплит — 30ms. Если модель не укладывается — оптимизируй: ONNX Runtime, TensorRT, квантизация, distillation. Или переходи на batch.
Мониторинг: data drift, model drift и деградация
Модель на проде неизбежно деградирует. Мир меняется: пользователи ведут себя иначе, данные сдвигаются, бизнес-процессы эволюционируют. Мониторинг — единственный способ поймать проблему до того, как бизнес потеряет деньги.
Три типа проблем: Data Drift — изменилось распределение входных данных. Пример: средний чек вырос из-за инфляции, новая возрастная группа начала пользоваться продуктом. Модель получает данные, которых не видела при обучении. Concept Drift — изменилась связь между фичами и таргетом. Пример: раньше «частые покупки» → лояльный клиент, но после пандемии «частые покупки» → паникёр, который скоро уйдёт. Те же фичи, другой смысл. Performance Degradation — метрики модели ухудшились. Это следствие data drift или concept drift. Ловишь через: падение accuracy/AUC на свежей разметке, сдвиг в распределении предсказаний, ухудшение бизнес-метрик (CTR, конверсия, revenue).
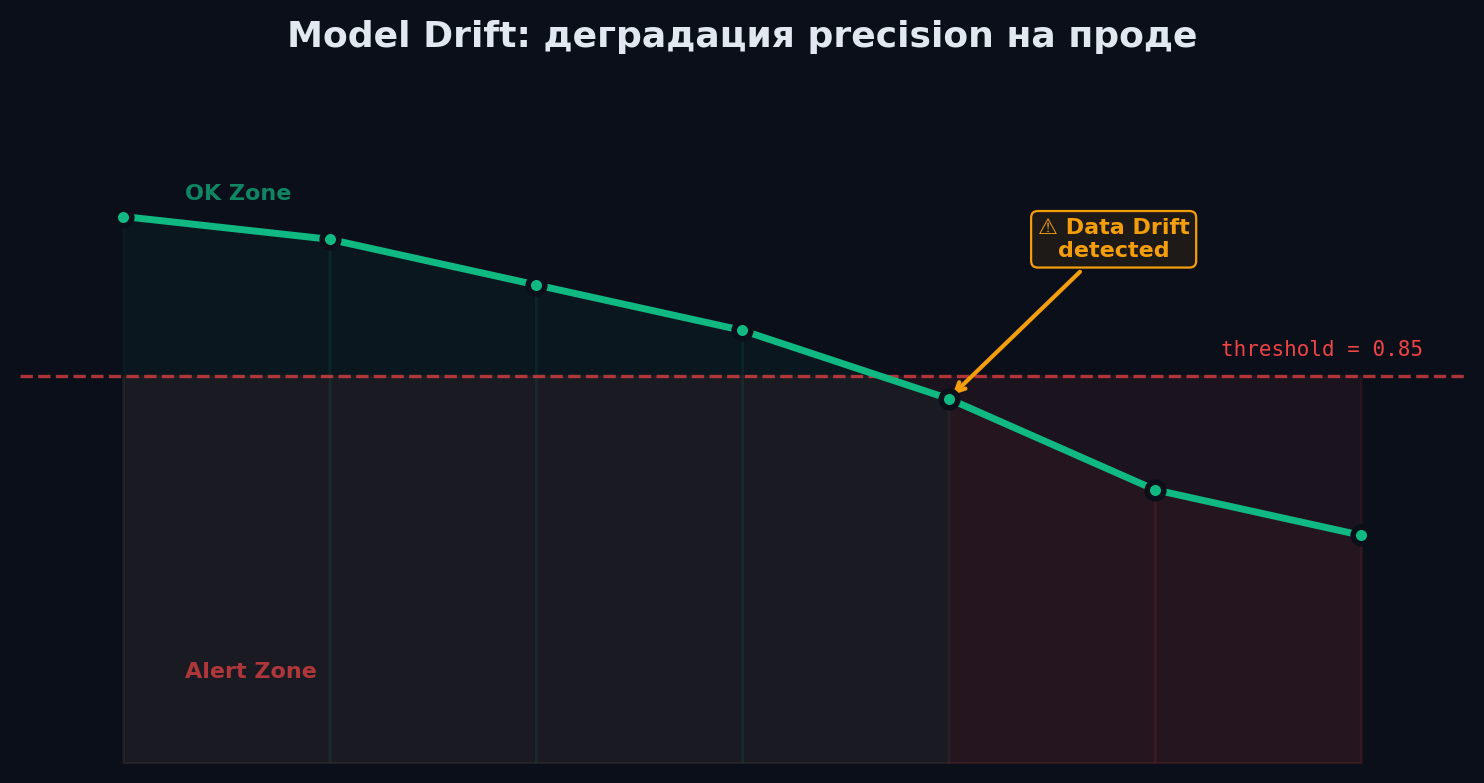
Как ловить drift: • PSI (Population Stability Index) — числовая метрика сдвига распределения. PSI < 0.1 — ок, 0.1-0.25 — внимание, > 0.25 — алерт. • KS-тест (Kolmogorov-Smirnov) — статистический тест: «распределение X_train и X_prod — одно и то же?» • Прокси-метрики — когда нет разметки (а на проде её почти никогда нет): confidence модели, доля предсказаний > 0.9, распределение классов, бизнес-метрики. Инструменты: Evidently AI (open-source, генерирует отчёты о drift), Grafana + Prometheus (дашборды и алерты), WhyLabs.
# Мониторинг с Evidently AI
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
report = Report(metrics=[DataDriftPreset()])
report.run(
reference_data=train_df, # данные обучения
current_data=prod_df, # свежие данные с прода
)
report.save_html("drift_report.html")
# → наглядный отчёт: какие фичи сдвинулись, насколькоЦикл реагирования: алерт (drift detected) → анализ (какие фичи? concept или data?) → решение (переобучить на свежих данных? добавить новые фичи? откатить модель?) → ретрейн → деплой через CI/CD → мониторинг. И цикл продолжается.
🎯 На собеседовании
Junior
Middle
Senior
Собираем всё вместе
MLOps — это непрерывный цикл: develop → train → deploy → monitor → retrain. Experiment tracking (MLflow, W&B) логирует каждый запуск. Model Registry версионирует готовые модели. CI/CD тестирует данные, модель и код. Feature store гарантирует одинаковые фичи в обучении и на проде. Model serving отдаёт предсказания batch или online. Мониторинг ловит drift до того, как бизнес потеряет деньги.
Если запомнить одну вещь из этой ноды: модель в Jupyter — это прототип, а не продукт. MLOps — это инженерная дисциплина, которая превращает прототип в надёжную систему. Без неё даже лучшая модель мира бесполезна.
Дальше на роадмапе: Docker — как упаковать модель в контейнер, Model Serving — архитектуры batch и online inference, Monitoring — детальный разбор drift detection и алертинга.
Материалы
Обзор инструментов и практик MLOps — хороший стартовый ресурс.
Быстрый старт с MLflow: логирование экспериментов, model registry.
Data drift, concept drift и как их ловить на проде.
Open-source feature store: offline + online хранение фичей.
Martin Fowler / ThoughtWorks — CI/CD для ML-систем.
Лекция Stanford: проектирование ML-систем от данных до мониторинга.